Summary
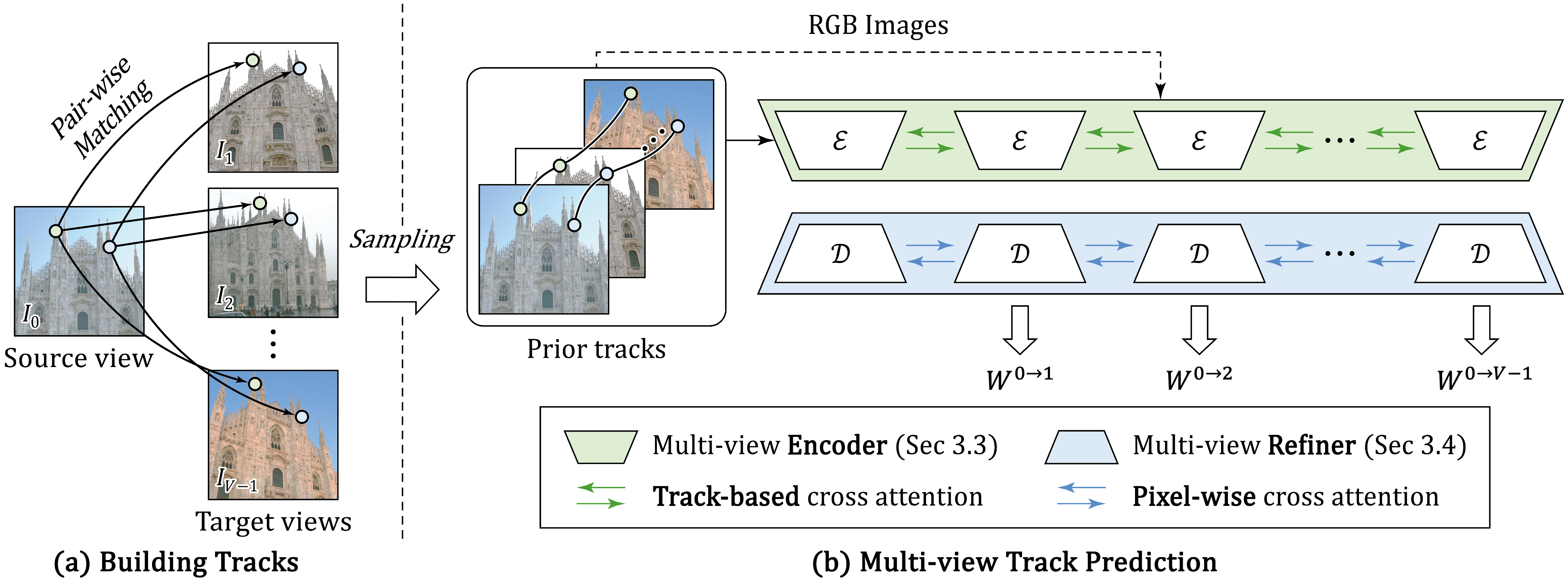
We propose MV-RoMa, a multi-view dense matching model that jointly estimates dense correspondences from a source image to multiple co-visible targets in a single forward pass. By embedding sparse geometric priors as track tokens into DINOv2 and applying efficient pixel-aligned attention at the refinement stage, MV-RoMa produces geometrically consistent multi-view tracks without the prohibitive cost of full cross-attention — enabling dense and accurate 3D reconstruction in the SfM pipeline.